1、首先在我的计算机桌面上找到7号OCR的图标,双击

2、打开上书的7号OCR,界面相似,与OFFICE软件的界面相似。 在菜单栏中打开文件。
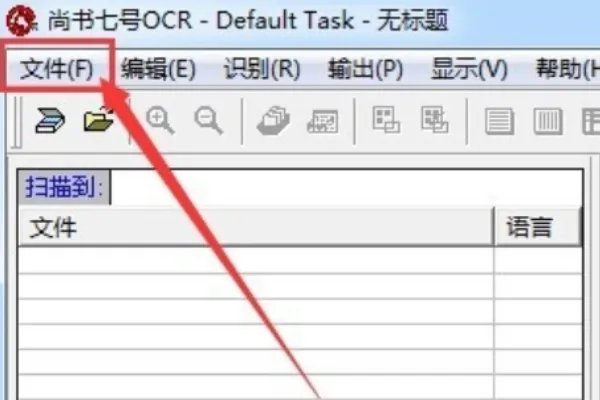
3、在文件下拉菜单中选择系统配置,以简化以后的操作
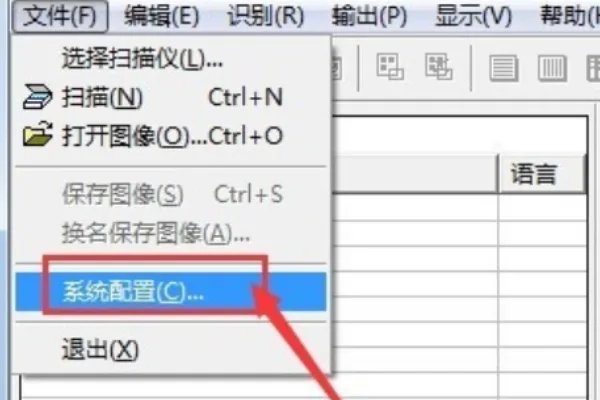
4、在“设置系统参数”对话框中,选择要获取的新图像语言,这里我选择“简化”,然后单击“识别”按钮。
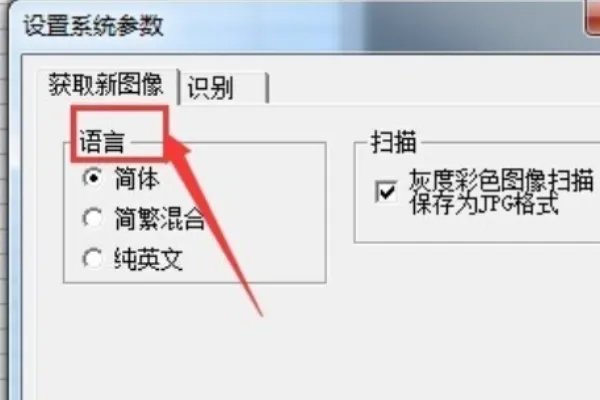
5、在识别选项中,选择自动倾斜校正
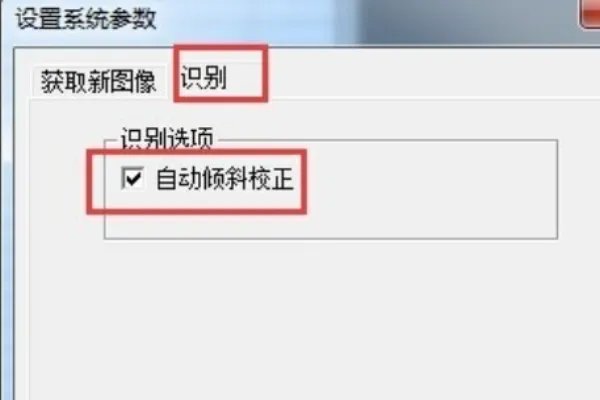
6、然后在菜单栏中选择显示。 这是打开软件后看到的显示窗口。 显示窗口因选项不同而有所不同。
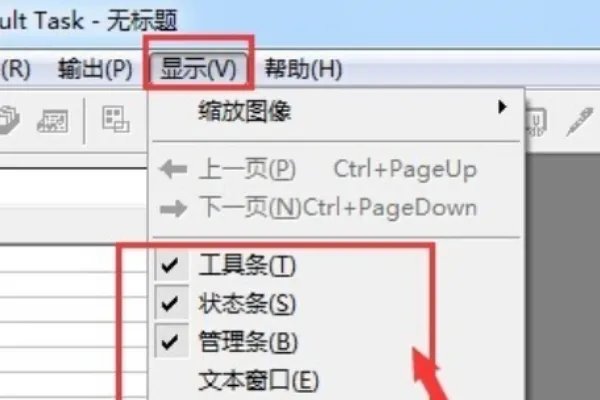
7、检查工具栏,状态栏,管理栏和文本窗口后,显示如下
1、首先在我的电脑桌面上找到这个尚书七号OCR的图标,双击
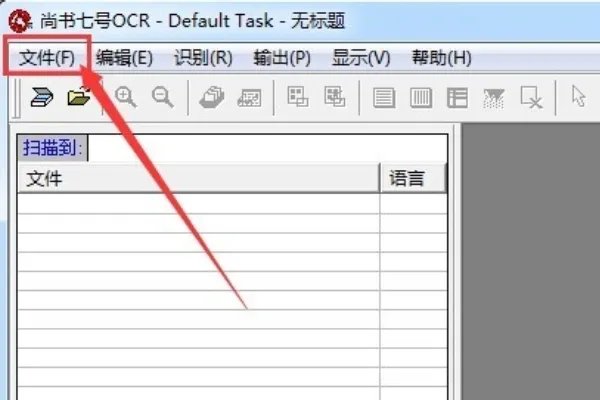
2、打开的尚书七号OCR,界面如图,和OFFICE软件界面差不多,打开菜单栏中的文件
3、在文件的下拉中选择系统配置,可以简化以后的操作
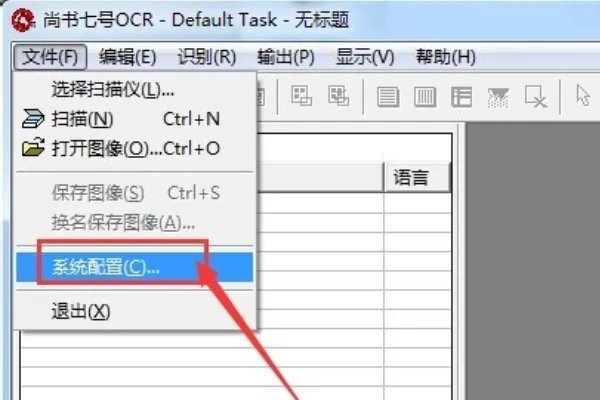
4、在设置系统参数对话中,对获取的新图像语言选择,在这里我选择的是简体,然后再点一下识别按钮
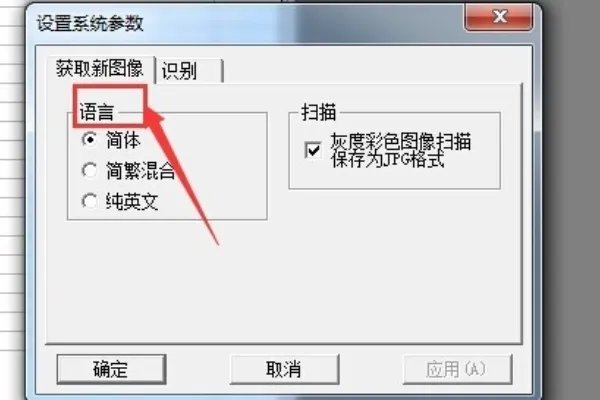
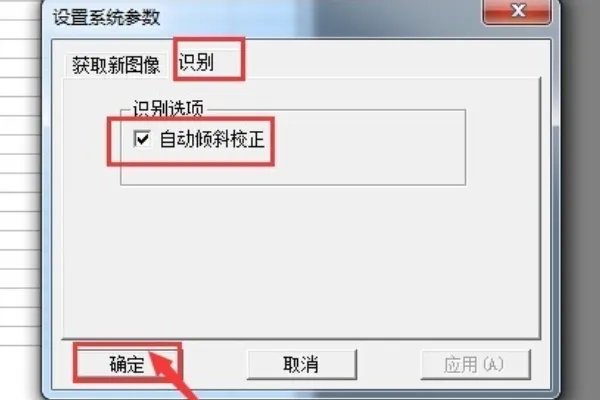
5、在识别选项中,选择自动倾斜校正
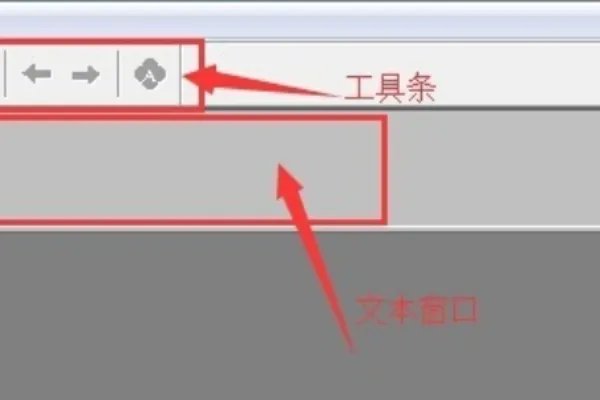
6、然后在菜单栏里选择显示,这个是我们打开软件后所见到的显示窗口,对不同的选项,显示窗口是不一样的
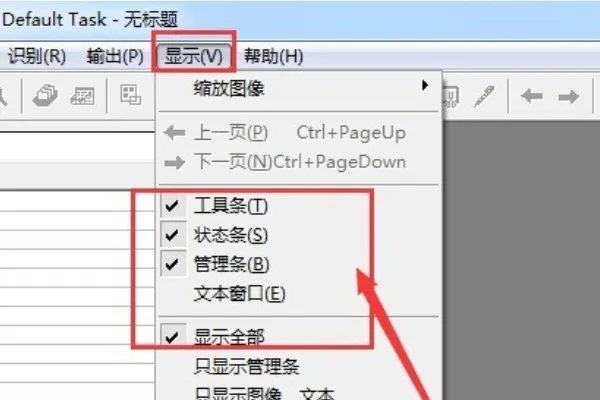
7、在工具条,状态条,管理条及文本窗口都打上对勾后,显示说明如下
首先把图片保存成分辨率300以上(别再低了)的jpg图片,tif好像也可以。
在尚书七号软件中打开图片,点击放大或者缩小调整好画面大小,然后选择区域,点击“识别”——“开始识别”,确定好后输出就可以了!
我也是刚琢磨好,祝愉快~~
用扫描仪扫描的文字图像,不能对个别文字进行编辑修改,在教学中,需要利用文字识别软件,将文字图像进行识别,将图像格式转化成文本格式,常见的文字识别软件有很多,主要功能基本相同,在此以ScanMaker
4850ii随机附送的尚书七号为例,介绍用文字识别软件对扫描仪扫描的文字图像进行识别的正确使用方法。
用尚书七号对文字图像识别转化的过程,利用其主菜单:“文件”、“编辑”、“识别”、“输出”可以很方便地完成。具体步骤为:
步骤1:获取文字图像文件。
选择“文件”菜单下的“扫描”或“打开图像”(将已经扫描好的图像文件打开)命令,打开图像文件。如果连接了多台扫描仪,可以选择“文件”菜单下的“选择扫描仪”命令,调用扫描仪。
步骤2:对扫描的图像页进行调整
选择“编辑”菜单下“图像页面的处理”子菜单下的“图像页的倾斜校正”(提供自动和手动实现方法)及“旋转”等命令,将扫描的图像页进行调整。
步骤3:版面分析与文字识别转化
版面分析,选择识别范围,在进行文字识别前要选择识别范围,识别过程的核心是“版面分析”。尚书七号的自动版面分析功能很强,对报纸杂志等复杂的版面,也能保持很高的分析正确率。
设置好后,直接点击“开始识别”的按钮就可以进行文字识别了。
步骤4:校对修改
自动识别完毕,识别结果的“文本窗口”会弹出,这个窗口能够提供识别结果的校对,为了校对方便,尚书七号增加了光标跟随显示原图像行的校对方法(如图3出现的黄色提示行的出现)。
提供的校对方法,一眼就能够看到图像原文和识别出文本的差别,如果发现识别有误,可以进行修改。
步骤5:输出
如果检查修改后确认无误,选择识别结果的“输出”菜单,输出的文件格式有:RTF、HTML、XLS、TXT,可以根据自己的需要选择对应的格式。如果用户想得到类似原文的识别结果,请选择RTF格式。把RTF格式输出的文件用WORD打开后,会发现几乎保留了原文的所有痕迹,包括原来页面中的彩色图像,都已经保留在WORD中了。


